自第一次输出“hello world”
「源代码如何变成可执行文件」的问题就一直伴随着我
本次以《程序员的自我修养—链接、装载与库》为参考,对这一过程做简单总结
简介
高级语言的出现使得程序员可以
尽量少考虑计算机本身的限制(如字长、内存大小、通信方式、存储方式)
相对的,程序员可以拥有更多精力在程序逻辑本身
结合高可移植性,高级语言使得开发效率得到极大的提高
可我们仍需学习高级语言到生成个执行文件到处理过程,我们才能够
更深刻地理解操作系统,同时对大型项目链接器类错误的处理游刃有余,
具体从源文件到可执行文件到过程,经过了预编译、编译、汇编、链接四个阶段
本文主要介绍前三个阶段,对于链接的更多细节问题,请跳转另一篇博文(TODO)
预编译
负责源代码中#开头的预编译命令
主要规则如下
- 处理预编译指令(
#ifndef) - 添加调试所需要的行号与文件名标识
- 插入库(include)
- 宏替换
- 去注释
编译
负责把预处理的文件分别进行
- 词法分析
- 语法分析
- 语义分析
- 生成中间代码
- 目标代码的生成和优化
词法分析
词法分析会按照预置好的规则将字符串分割为一个个记号
记号分为关键字、标识符、字面量(数字、字符串等)、特殊符号(加号、等号等)
以array[index] = (index + 4) * (2 + 6)为例
词法分析会将代码分割为array、[、index、]等记号,并分类存放(标识符置符号标、数字置文字表等)
词法分析是为之后的步骤服务的
语法分析
语法分析使用「上下文无关语法」的分析手段产生「语法树」
所谓语法树就是以「表达式」为节点的树
上例中的代码就是一个由赋值、加法、乘法、数组、括号表达式组成的复杂语句
经过语法分析后生成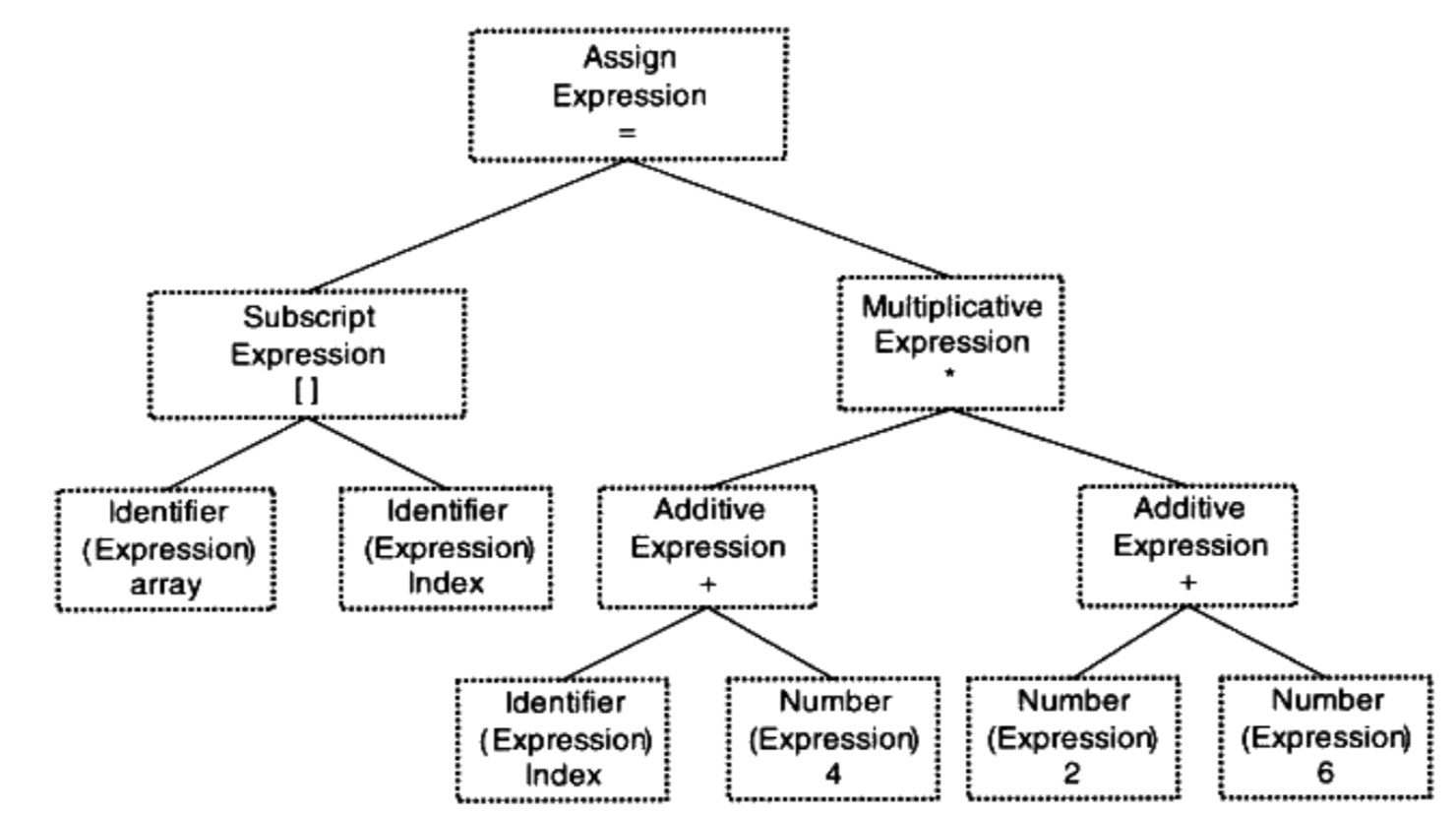
整个语句被认为是一个赋值表达式,赋值表达式左边是数组表达式,右边是乘法表达式
数字是最小的表达式,被作为语法书的叶节点
语法分析过程中会确定运算符的优先级和含义(*号可以表示取指针内容,也可以是乘法)
如果出现括号不匹配、缺少操作符的问题,编译器会报告语法分析过程中的错误
语义分析
语法分析仅仅针对语法层面判断是否合法,并不分析表达式是否真的有意义
(C中指针做乘法运算是合法的,但没有意义)
语义分析分为静态语义分析和动态语义分析
动态语义分析指运行期间的语义问题,如0作为除数进行运算
编辑器该阶段只进行静态语义分析
静态语义分析包括包括声明与类型的匹配、转换,包括:
- 浮点型表达式赋值给整型表达式,隐含了类型转换,此时语义分析需处理语法树
- 浮点型表达式赋值给指针,模式不匹配,编译器报错
语义分析后整个语法树的表达式都被标示了类型
如果有隐含的类型转换,语义分析会在语法树插入相应的转换节点
上例中所有表达式类型都是整型,不需要转换,此时语法树为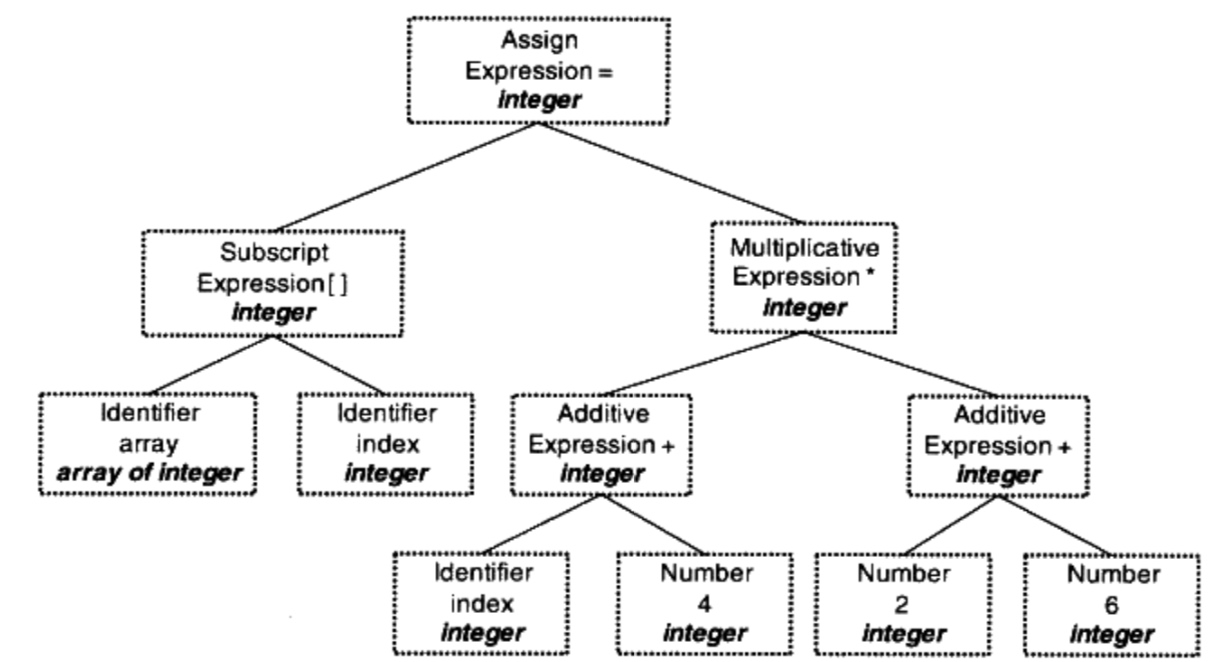
中间语言生成
此时会进行编译器多层优化中的源码级优化
形如(2 + 6)的表达式的值在编译期间就可以确定,可以优化
该阶段语法树会被转换为「中间代码」,即语法树的顺序表示
常见的中间代码分为「三地址码」和「P-代码」
最基本的三地址码为 X = Y op A,表示Y,Z进行op操作后赋值给A
上例中的语法树转换成三地址码为
1 | t1 = 2 + 6 |
优化后为
1 | t1 = index + 4 |
中间代码是最后的与目标机器运行环境无关的代码
因此中间代码使得编译器可以分为前端和后端
- 编译器前端负责产生与机器外观的中间代码
- 编译器后端负责将中间代码转换为目标机器码
这样跨平台编译器可以使用一个前端、不同后端
目标代码的生成和优化
中间代码的生成意味着接下来的工作属于编译器后端
编译器后端主要包括目标代码生成器和目标代码优化器
对于上述例子,可能会生成以下汇编代码
1 | movl index, %ecx |
代码优化器处理后为
1 | movl index, %edx |
上述若干个步骤后,源代码终于被编译成了目标代码
但此时目标代码存在问题:index和array的地址还没有确定
index、array的定义和源代码在同一个编译单元里,则可以直接为index和array分配空间
事实上所有的源代码都在一个编译单元是不可能的
所以现代编译器在将每个源代码编译成未链接的目标文件后,随后还要由链接器链接起来形成可执行文件
汇编与链接
转机器码
在链接前,还要经历汇编代码转成机器码的过程。
汇编没有分析、没有优化,只是通过预设规则将汇编代码一一转换为机器码
此时若干源文件经过一系列处理已经变成若干个目标文件,在linux下后缀为.o
一个目标文件中至少有两个段:代码段和数据段,目标文件的内容不在本文详细展开
unix环境下主要有三种类型的目标文件
- 可重定位文件:二进制代码和数据,由各个数据节(section)构成,从地址0开始
- 共享的目标文件:一种特殊类型的可重定位目标文件,用于动态加载链接
- 可执行文件:可以被操作系统创建一个进程来执行的文件。汇编生成是可重定位文件
后两种目标文件的创建则是链接程序的工作
代码的链接
链接的工作即是把一些指令对其他符号的地址的引用加以修正
其过程主要包括了地址空间分配、符号决议(或名称绑定)和重定位
地址空间分配不再赘述,链接器接下来主要需要做符号决议或名称绑定
决议/绑定
我们的程序肯定会调用各类库,可执行文件与库代码之间联系的处理
这便是链接所需做的第一步:符号解析,即符号决议或名称绑定
决议主要指的是静态链接,绑定主要指的是动态链接
静态链接:在程序执行之前完成所有的组装工作,生成一个可执行的目标文件(EXE文件)。
动态链接:在程序执行被装入内存之后完成链接工作,会独立一个dll文件,运行时灵活“装卸”
静态链接与动态链接限于篇幅不在此详细展开
文本仅介绍这一阶段牵扯到的符号表的概念
之前提到汇编生成的目标文件为可重定位文件,unix环境下格式为ELF
一个典型的ELF文件包括
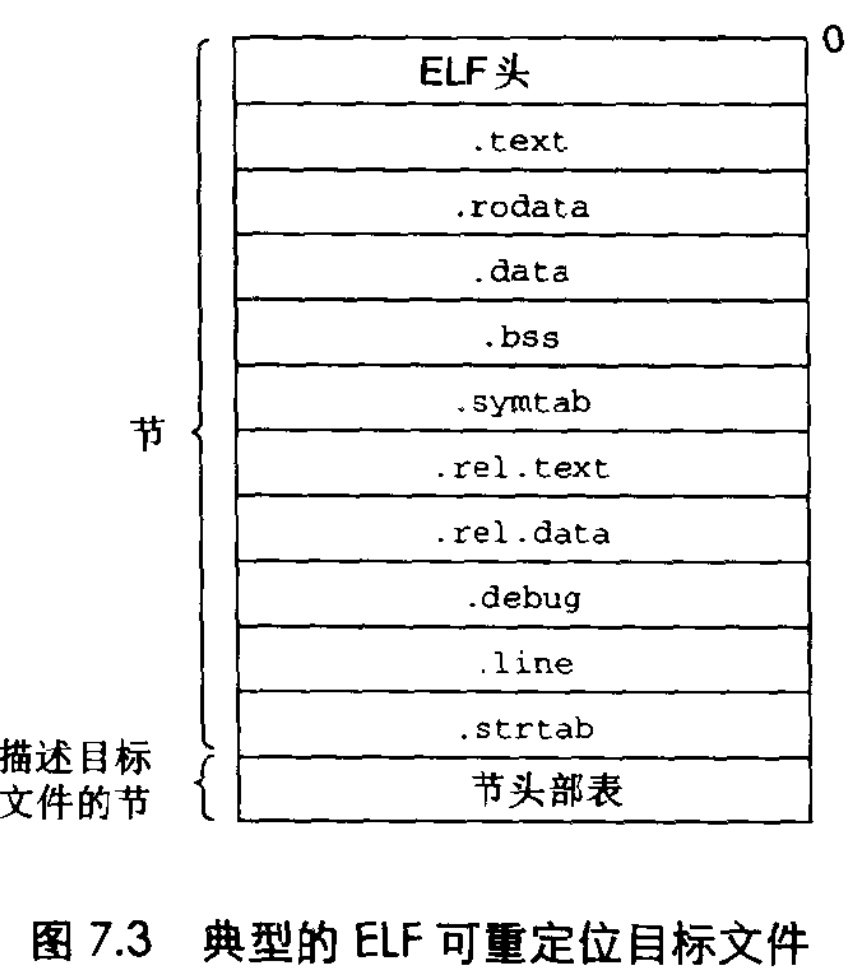
ELF具体各节意义不在此详细展开
但值得强调的是每个可重定位目标模块m都有一个符号表,包含其所定义的、引用的符号信息
以C为例,符号分为三种
- 全局符号 被m定义,能被其他模块引用 对应非静态的C函数和非静态的C的全局变量
- 外部符号 由其他模块定义,被m引用 对应定义在其他模块中的C函数与变量
- 本地符号 带static属性的C函数或全局变量,在m内可见,不可以被其他模块引用
为了用户能够定义自己的符号同时不和库中的冲突,还有强符号、弱符号的概念
库中定义的弱符号可以被用户定义的强符号覆盖,从而使程序可以使用自己定义版本的库函数
强弱符号在链接时遵循
- 不允许强符号被多次定义,否则报错重定义
- 如果符号在某个文件中是强符号,在其他文件中是弱符号,则选择强符号
- 如果一个符号在所有文件中都是弱符号,则选择其中占用空间最大的
相关还有强引用和弱引用的概念
- 强引用 目标文件引用了外部符号,在链接时若未找到定义,报错;对该外部符号的引用为强引用
- 弱引用 目标文件引用了外部符号,在链接时若未找到定义不报错;对该外部符号的引用为弱引用
有了符号表,词啊方便了链接程序进行之后重定位的工作
经过静态、动态链接,程序已经集合了所有需要的模块,最后的工作就是通过重定位相互联系起来
重定位
正如编译最后所说:所有的程序代码不可能放置在一个模块
各个模块之间如何联系起来,生成最后的代码,这是链接的第二步工作:重定位
回顾一下现在遇到的问题:
一个程序被分为多个模块后,模块之间不知道如何组合,即模块之间如何通信的问题。
模块之间通信有两种方式:模块间的函数调用、模块间的变量访问
函数访问需要目标函数的地址,变量访问也需要知道目标变量的地址
两种方式可以归结为一种方式:模块间符号的引用
处理不同模块符号间引用即对定义在其他目标文件中的函数/变量调用对应地址重新调整
假如有全局变量var在目标文件A中,在目标文件B中访问该全局变量
具体在B中原汇编代码有
1 | movl s0x2a, var ;将变量var赋值0x2a(42) |
编译后得到机器码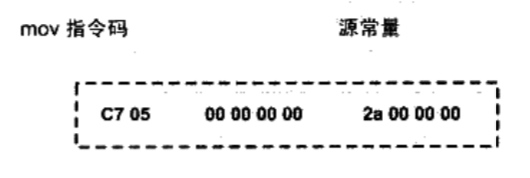
在编译B时,编译器并不知道var的地址,因此将这条mov指令的目标地址置0,在链接器处理时,才将var的地址确定下来,修改指令的目标地址为0x10000
这个修正的过程中即为重定位,每个要被修正的地方叫重定位入口
得到可执行文件
经过上述步骤,源代码被一步步处理为机器码,在最后将各个目标文件联系起来
终于得到了最后的二进制可执行文件
后缀为.o的目标文件内部的详细处理
C++的符号处理与函数签名
动态链接的各种细节
更多信息限于篇幅不在此展开
向大家推荐图书:《程序员的自我修养—链接、装载与库》以及《深入理解计算机系统》第七章